Abstract
High-fidelity 3D scene reconstruction has been substantially advanced by recent progress in neural fields.
However, most existing methods require per-scene optimization by training one network from scratch each
time.
This is not scalable, inefficient, and unable to yield good results given limited views.
While learning-based multi-view stereo methods alleviate this issue to some extent,
their multi-view setting makes it less flexible to scale up and to broad applications.
Instead, we introduce training generalizable Neural Fields incorporating scene Priors (NFPs).
The NFP network maps any single-view RGB-D image into signed distance and radiance values.
A complete scene can be reconstructed by merging individual frames in the volumetric space
WITHOUT a fusion module, which provides better flexibility. The scene priors can be trained on large-scale
datasets,
allowing fast adaptation to the reconstruction of a new scene with fewer views. NFP not only demonstrates
OTA scene reconstruction performance and efficiency, but it also supports single-image novel-view synthesis,
which is under-explored in neural fields.
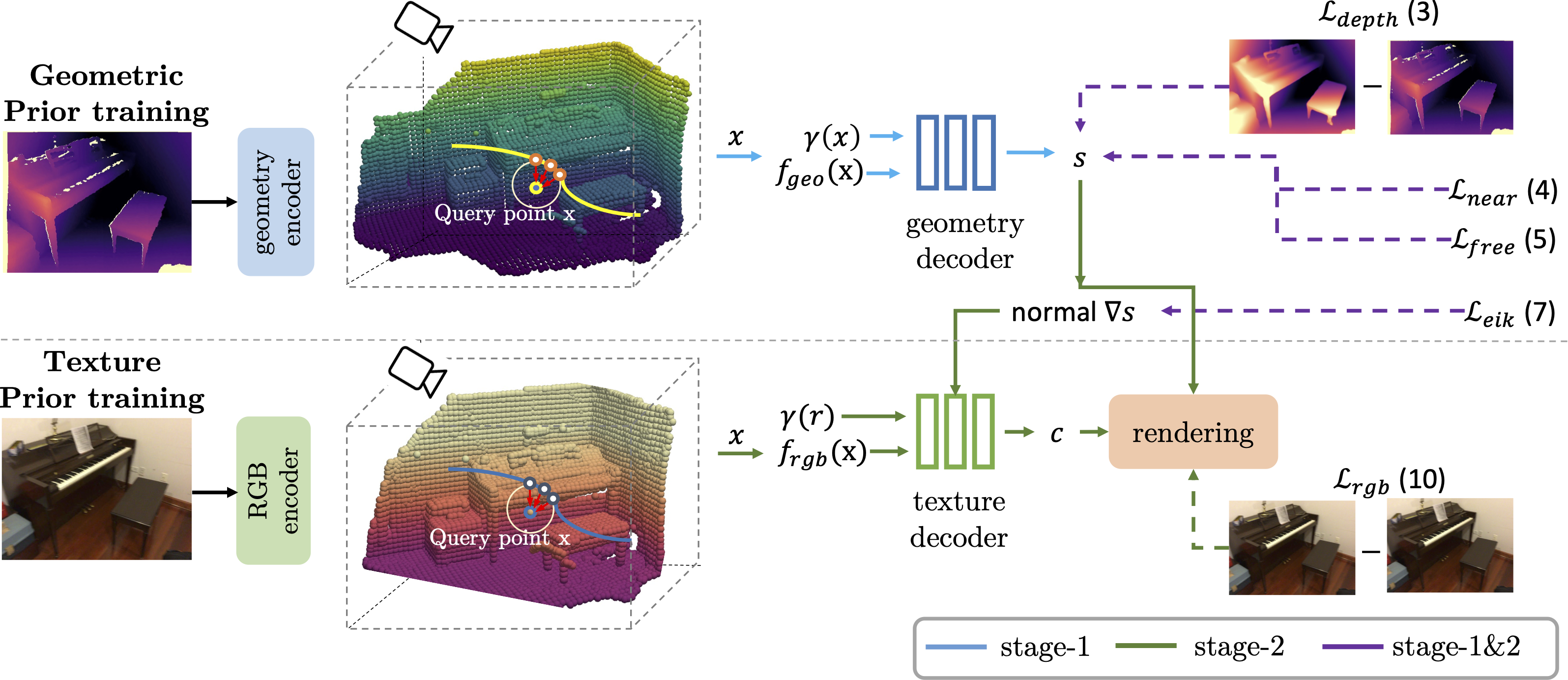
Given the RGBD input, we first extract the geometric and texture pixel feature using two encoders. Then, we construct the continuous surface representation upon the discrete surface feature. Next, we introduce a two-stage paradigm to learn the generalizable geometric and texture prior, optimized via multiple objectives. Finally, the learnt prior can be further optimized on a specific scene to obatin a high-fidelity reconstruction.

